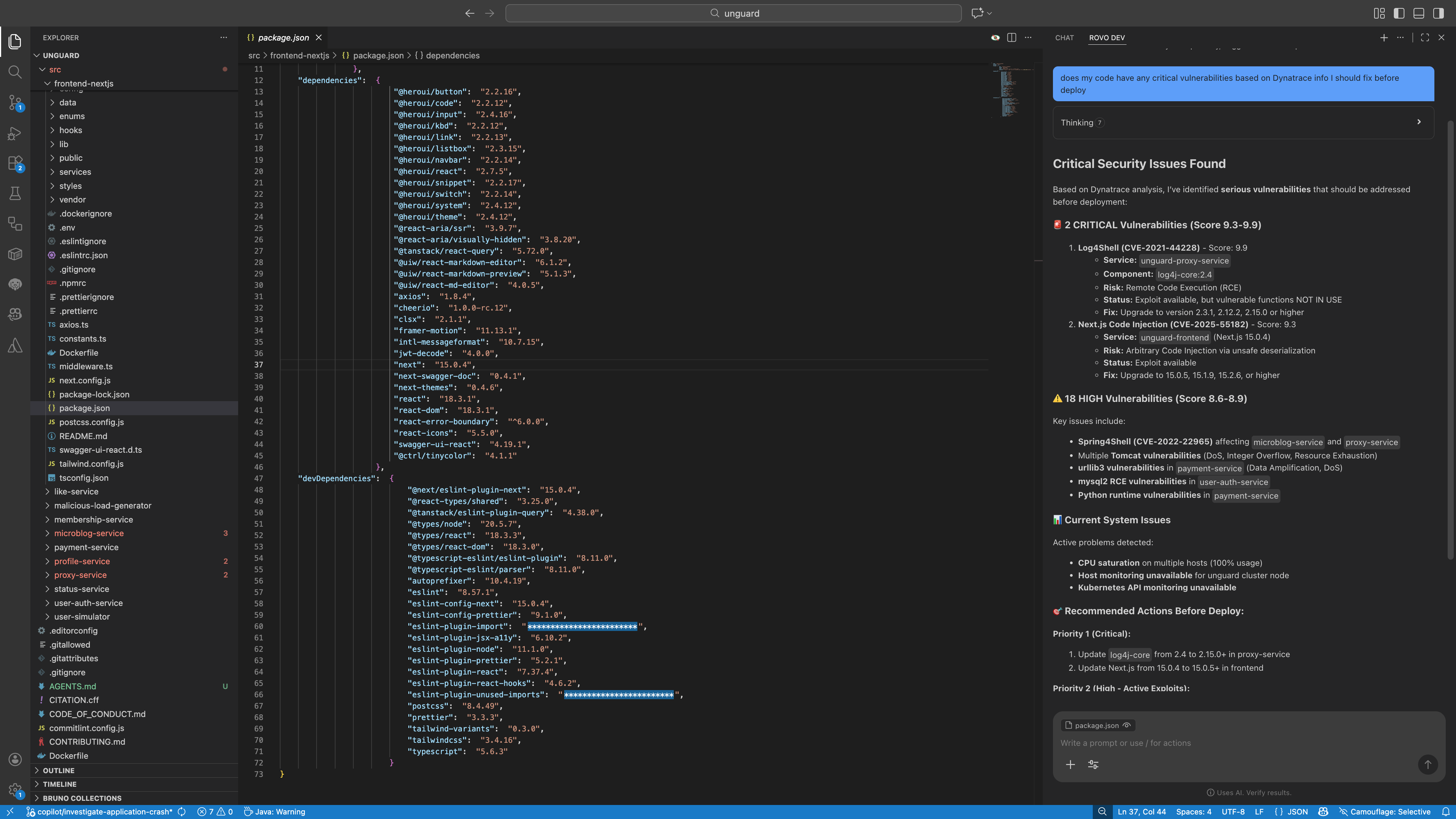
Runtime Vulnerability Analytics
Continuously detect and reprioritize runtime vulnerabilities using real-time context to reduce risk, eliminate noise, and accelerate remediation.
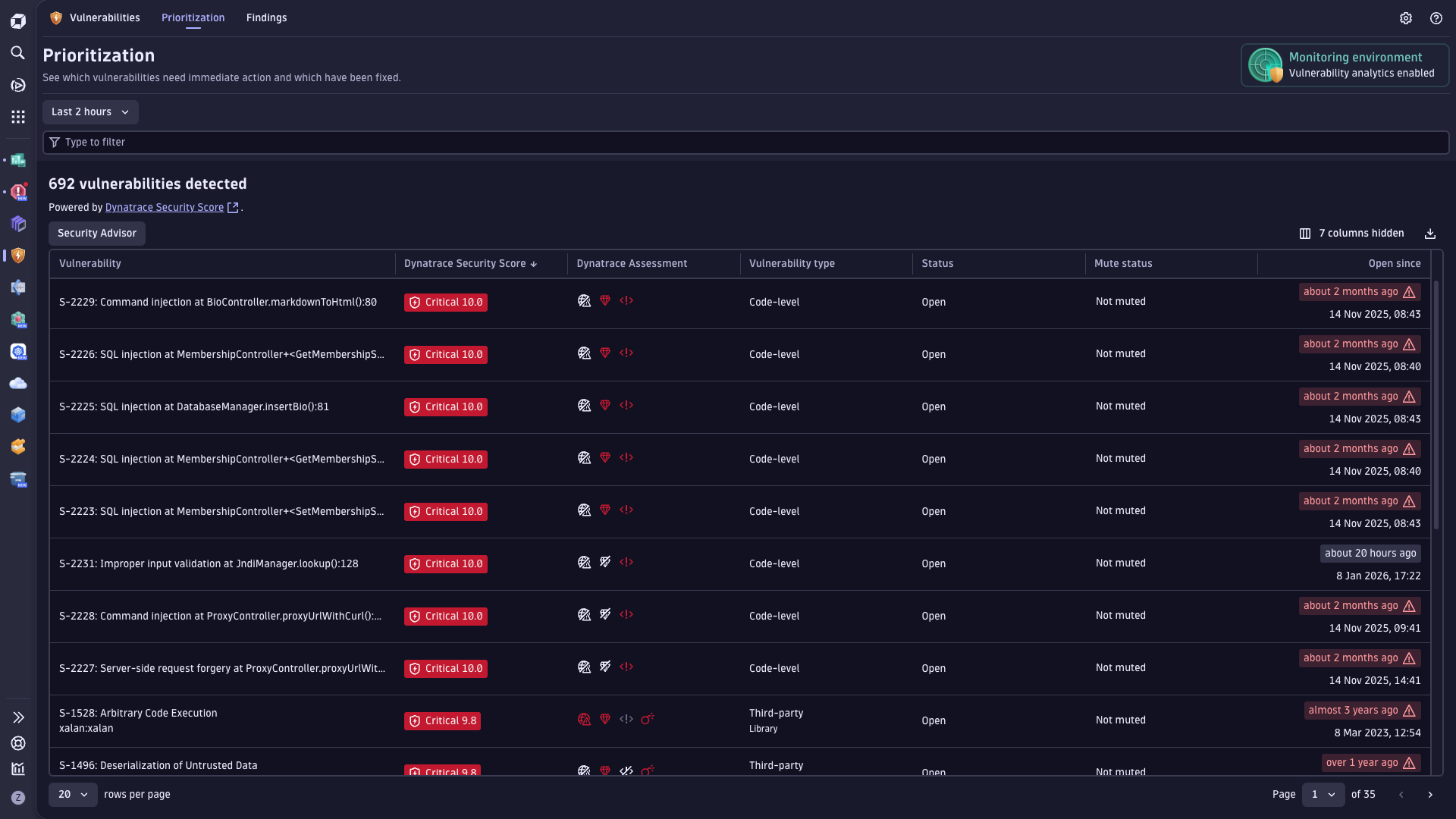

Get better reliability of services in production
- Continuously protect production reliability by detecting and prioritizing runtime risks that directly impact live services.
- Maximize Kubernetes uptime through deep visibility, rapid issue detection, and automated remediation to reduce MTTR.
- Accelerate root-cause analysis with unified observability and security insights across applications and infrastructure.
- Eliminate blind spots by integrating and contextualizing data from across your digital ecosystem to prevent disruptions.
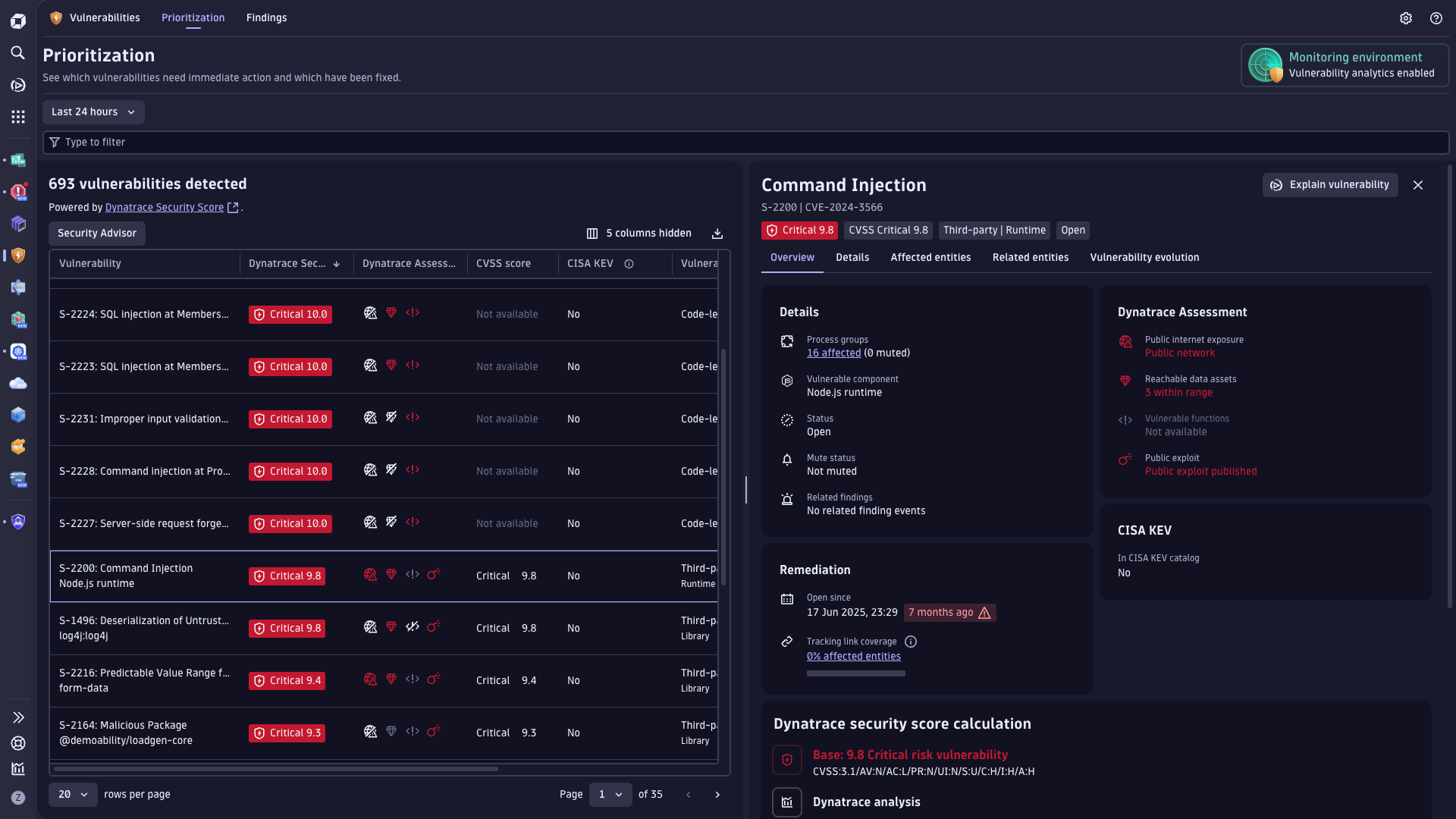
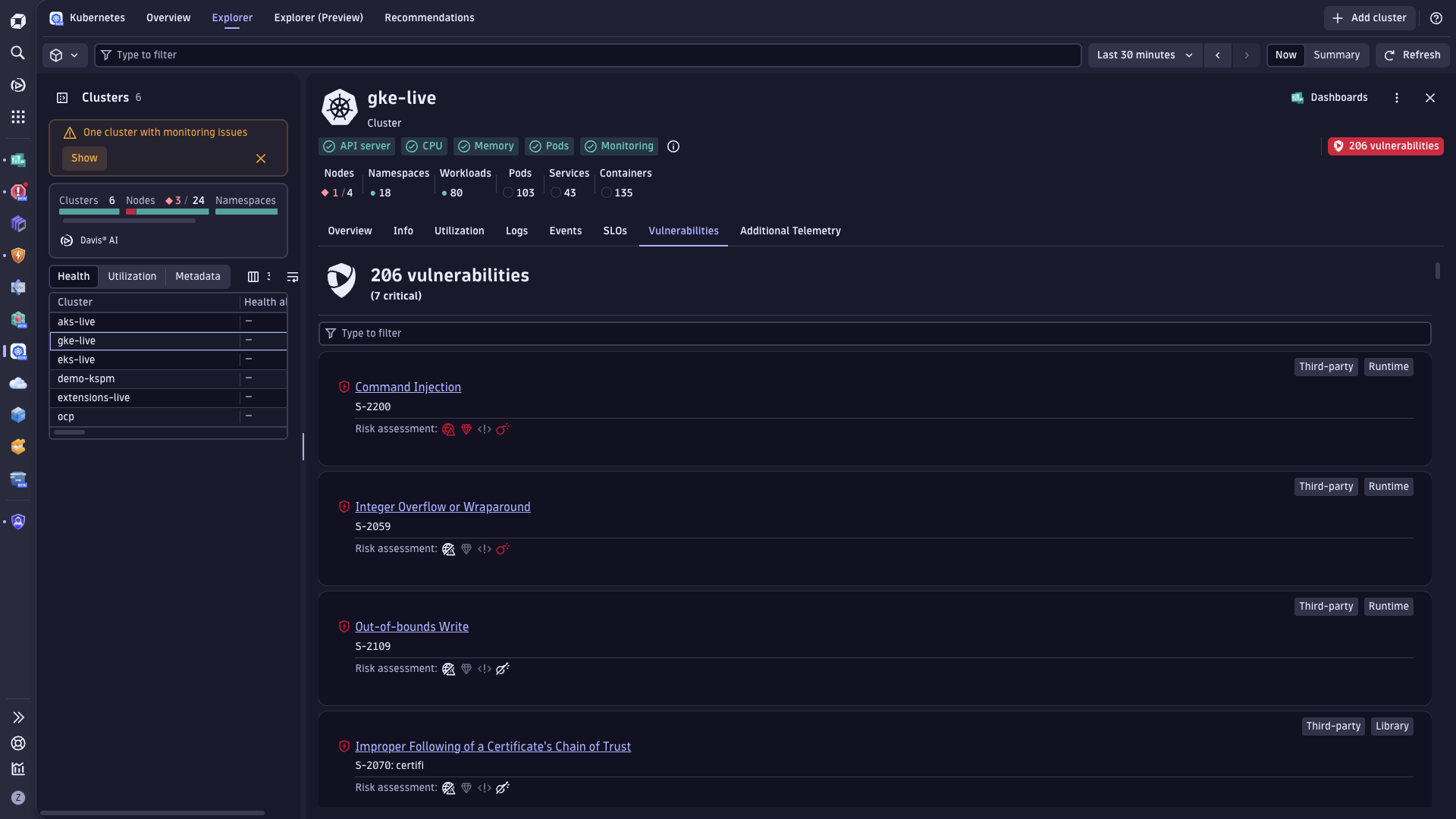
Maximize service uptime for Kubernetes workloads
- Reduce Kubernetes outages and service degradation by proactively identifying and mitigating risks before they escalate into major problems or impact users.
- Detect, investigate, and resolve issues faster to significantly lower mean time to resolution (MTTR).
- Gain end-to-end visibility into application behavior, configuration risks, and third-party dependencies to eliminate blind spots.
- Restore services automatically using workflows that speed remediation and reduce manual effort.
Automate security remediation with agentic workflows
- Shift left with runtime truth by giving developers proactive vulnerability insights and recommendations during development directly in their IDE.
- Automatically triage and prioritize vulnerabilities using real runtime risk, service impact, and environmental changes.
- Guide and accelerate remediation with precise fix recommendations and agentic workflows.
- Reduce noise and manual effort through intelligent suppression of non-actionable findings and a closed-loop validation process.